調査の信頼性を担保するために
調査における「信頼性」とは、測定(調査)結果が正確で安定したものであるかの程度です。言い換えれば同じデザインの調査を繰り返したとき、同じ(ような)結果が出るということです。違う結果が出た場合(たとえばブランドの認知度が10%ポイント上がった)、そこには何らかの原因系がある(広告の効果が出た、配荷率が上がったなど)と自信を持って言えることです。
測定(調査)にかかわる誤差は系統誤差と偶然誤差に分離できます。系統誤差とは測定に対して一定の影響を及ぼし、測定が行われるたびに同じように観測スコアに影響を及ぼす安定した因子を指します。調査結果の首尾一貫性が損なわれることはありません。一方、偶然誤差は測定が行われるたびに異なる形で観測スコアに影響を及ぼす一時的要因(個人的要因、状況的要因)です。偶然誤差が調査の信頼性を低下させるのです。
調査における「誤差」の潜在的な原因
調査の企画から実査、集計、分析、報告にいたる調査設計のプロセスにおいて、誤差(Error)を招く非常に多くの潜在的な原因があります。リサーチャーはこれらの誤差がどのようなものであるかを理解し、誤差の要因(特に偶然誤差)をコントロールし、最小に抑える努力をする必要があります。
我々が調査から得られる、ある変数の平均や割合の数値と母集団における真の値との差を全誤差といいます。全誤差の少ない調査が「標本代表性」の高い調査であるということができます。調査プロジェクトのプロセスを通して起こりうる誤差の原因は図表1のように分類・整理できます。
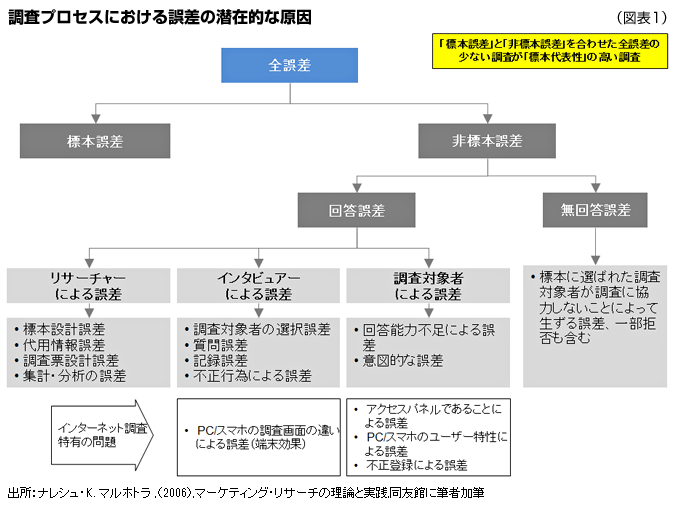
まず、全誤差は(無作為)標本誤差と非標本誤差に分けることができます。標本誤差は母集団の全数を調査するのではなく、母集団の一部(標本)しか調査しないために生ずる誤差です。標本誤差の大きさは(無作為に抽出された場合)一定の式で計算することができます。一方、非標本誤差は標本抽出以外の原因によるもので、様々な理由から生じます。
認識して頂きたいのは図表1に示したように、誤差にはこれだけ多くの潜在的な原因があるということです。特に非標本誤差は標本誤差よりも一層大きな問題をはらんでいる可能性があります。標本誤差は計算できますが、非標本誤差は推定できないのです。また短絡的に大きなサイズの標本を用いれば標本誤差は小さくなりますがインタビュアーによる回答誤差(非標本誤差)はかえって大きくなってしまう可能性もあるのです。ですからリサーチャーはひとつひとつの誤差を最小に抑え、結果として全誤差を小さくする努力をしなければならないのです。調査プロジェクトの企画から分析・報告までの各プロセスの管理は、全誤差をミニマイズするのだという意識が大事です。
非標本誤差について
非標本誤差はさらに無回答誤差と回答誤差からなります。無回答誤差は標本に含まれた調査対象者のうち、何人かが回答しない場合に生じます。無回答誤差の主な原因は拒否と不在です。即ち「回収率」(最近、住民基本台帳のような整備されたサンプリングフレームが調査で使えなくなったりして、回収率の概念が希薄になっていますが)の問題です。これをミニマイズすることが調査の精度を高めることに繋がります。参考までに、「回収率を高める工夫」を紹介します。

回答誤差は調査対象者が不正確な回答をしたり、調査対象者の回答が誤って記録されたり、分析されたりする場合に生じます。回答誤差の原因は、リサーチャーによる誤差、インタビュアーによる誤差、調査対象者による誤差に分けられます。これらについて、以下順次説明します(引用:日本マーケティングリサーチ協会 (編集), JMRA(編集), (2004),マーケティング・リサーチ用語辞典, 同友館)。なお、非標本誤差のうち、過大または過小のどちらか一方に偏って生じやすい誤差のことを「バイアス」(偏り)といいます。
インターネット調査においては、これらの他いくつかの潜在的な誤差がありますが、この件については次回述べることとします。
リサーチャーに起因するもの
リサーチャーによる主な誤差には次のようなものがあります。
- 標本設計誤差・・・母集団の定義、抽出枠、抽出方法・手続き、推定方式など。たとえば、電話帳は固定電話所有者の母集団を正確に表していないので抽出枠としては不完全であるのに使ってしまう。B2B調査で層化抽出ではなく単純無作為抽出を採用するなど
- 代用情報誤差・・・本来求められている情報が入手困難なために入手可能な情報で代用する。たとえば本来は新製品の購入者に質問しなければならないのに購入者の出現率が低いので認知者に質問してすませる
- 調査票設計誤差・・・長すぎる調査票、不適切な質問順序・質問文・選択肢・回答記入欄、誘導質問・ダブルバーレル質問(2つの質問内容を1つの質問文にしてしまう・・・この薬は胃を荒らさずに速く効くと思いますか?)など。参考までに「質問文作成の際の留意点」を図表3で紹介します。
- 集計・分析の誤差・・・調査票の原データが調査結果に変換される際の不適切な統計処理がなされることに起因する誤差

インタビュアー・実査に起因するもの
インタビュアーに起因する誤差としては次のようなものがあります。
- 調査対象者の選択誤差・・・インタビュアーが調査設計で特定された調査対象者以外を選択する
- 質問誤差・・・いくつかの質問をし忘れる、質問文どおりに質問しない、インタビュアー独自の判断で質問の表現を変えたり、回答を誘導する、枝分かれ質問の指示を間違える、十分なプロービングを行わないなど
- 記録誤差・・・調査対象者の回答を聞き違える、自由解答を間違った解釈をして調査票に記入する、回答を勝手に省略する・回答の一部しか記録しないなど
- 不正行為による誤差・・・調査対象者の回答の一部もしくはすべてを捏造する
調査対象者に起因するもの
調査対象者に起因する誤差としては次のものがあげられます。
- 回答能力不足による誤差・・・調査のテーマが身近なものでない、記憶が不確か、長時間の面接や似たような質問の繰り返しによる飽きなど
- 意図的な誤差・・・調査対象者に正確な情報を提供する意思がないことから生じる誤差です。社会的に受け容れられる回答を出したい、恥をかきたくない、インタビュアーを喜ばせたいという理由で調査対象者は正直に回答しないことがあります。
またプライベートな質問には進んで答えようとはしないし、逆に高いステータスシンボルとなるような製品・ブランドには「持っている・使っている」と答えることもあります。
回答バイアス
図表4に人間が本来持っている心理的・社会的特質や知覚の特性について整理しました。
系統誤差である場合が多いのですがリサーチャーは調査票の設計時・分析時にこれらの特性を心得ておくことが求められます。

ハロー効果を例にとりますと、最初に全体評価や購入意向の質問に対し良い(悪い)評価を与えると、それに続く属性・イメージの質問にも実際よりも良い(悪い)評価を与えます。属性・イメージの評価セットのなかでも最初に回答した属性の評価が後に続く属性の評価に影響を与えます。またトレンドの調査がある場合、属性の質問順序を変えただけでトレンドは壊れてしまいます。そうならないために質問するブランドや属性の質問順序をランダマイズする、属性の質問順序をむやみに変えないなどの措置をとる必要があります。言い換えますと調査タイプごとにプロトコルを確立することが重要です。
次回は「インターネット調査における信頼性について」の予定です。