インターネット調査における信頼性の担保
前回は調査における潜在的な「誤差」のうち、特に回答誤差の原因をリサーチャーによる誤差、インタビュアーによる誤差、調査対象者による誤差に分解して解説しました。今回は最近の「インターネット調査(以下ネット調査)を取り巻く環境の変化に対応した信頼性の担保」をどうすべきか、という視点から解説したいと思います。本稿は2015年の夏に行った弊社主宰のクライアントセミナー「スマートフォン時代のMixed Mode Researchのご提案」の内容をアップデートしたものが主になっています。
ネット調査の環境変化
スマートフォン(以下スマホ)の保有率が上がることにより、ネット調査に回答するデバイスとしてスマホを使う人も急速に増加しています。楽天インサイトのアンケートモニターにおいても2016年1月の実験調査では20代の男性の約4割、20代女性の6割強がスマホで回答しています。こうした環境変化に対して、現在のネット調査の調査設計は「PC端末からの回答想定した設計」と「スマホ端末からの回答に制限した設計(スマホ調査)」の2つが主流のようです。前者においては、スマホ端末からの回答を想定しておらず、回答画面がスマホ用に最適化されていないため、次のような問題を抱えています。
- スマホ端末からの回答品質が低下する恐れがある
- スマホからの回答はPCからの回答に比べ、質問の「一覧性」が低くなりがちで特定の選択肢への回答が集まる可能性がある
- スマホ用に最適化されていない質問に回答しなくてはならないことから、回答負荷が大きくなる
- 結果として回答時間が長くなりがちである(実験調査ではPCからの回答時間の1.5倍)
ただし、現在のところ、スマホからの回答品質はPCからの回答品質に比べ、決して劣ってはいません。MA回答への回答数、自由回答の文字数などむしろPCからのそれらを上回っています(アンケートモニターのロイヤルティが高いためと思われます)。
- スマホ端末からの回答負荷の大きい調査を将来的に続けていくと、スマホからの調査協力率の低下を促進し、将来的には特に若年層から一定の回答数を確保することが困難になる恐れがある
- 各回答端末に最適化された設計ではないため、現状のままでは回答する端末により、回答結果に差が出る恐れがある
またこの「PC端末からの回答を想定した設計」には過去の調査との継続性という観点から、PC端末からの回答だけに制限して調査を実施するといった方法がとられることも見られます。しかしながら、スマホからの回答者が増加している状況を考えると、スマホ端末からの回答者を除外することはサンプルが偏り、決して適切な方法であるとはいえません。
一方、後者の「スマホ端末からだけの回答に制限した調査」の問題点は次のように整理できます。
- 若年層の回答は収集しやすくなるものの、40代以上の層の回答が集めづらくなり、サンプル構成が偏る
- 質問数をあらかじめ5~20問に設定している調査設計が多く、必ずしも現状の調査ニーズに合っていない
このように実査環境が変化しているにもかかわらず、適切な対応が遅れがちなのが現状です。リサーチャーは「PC端末からの回答とスマホ端末からの回答の違い」を理解し、変化に対応した最適な調査設計を提案していくことが求められます。
PC端末からの回答とスマホ端末からの回答の違い
PC端末からの回答とスマホ端末からの回答の違いがあるとしたら、その違いは何からくるのでしょうか?両者の回答の違いは「標本枠効果=Sampling frame effect」と「端末効果=Mode effect」の2つの効果によるもので、両者の回答の違いはこの2つの効果を掛け合わせた結果として説明できます。
標本枠効果(Sampling frame effect)・・・仮説:スマホ回答者とPC回答者には「人の特性の違い」があり、その違いから回答結果に違いが出る。
詳細は省きますが、実験調査の結果から、スマホ端末から回答する人のほうがPC端末から回答する人に比べて、より情報感度が高く知識やイメージが豊富です。
端末効果(Mode effect)・・・仮説:同じ属性の回答者でも、回答端末が異なると、画面の見え方や画面の大きさの違いから回答結果に違いが出る。
これに関しても実験調査を行いました。通常スマホ端末から調査に協力している人を対象者とし、半数の対象者には敢えてPC端末から回答してもらい、残り半数は通常通りスマホ端末から回答してもらって回答結果の違いを検証しました(対象者の属性は同じ)。質問項目は広告静止画像と広告動画(音声付)について同じ質問で評価してもらいました。結果は静止画像及び動画ともに広告のインパクトに関連する項目(迫力がある、躍動感がある等)及び広告の中のメッセージの想起率は、回答画面の大きいPC端末からの回答のほうがスマホ端末からの回答よりもスコアが高くなりました。つまり同じ属性の人であっても回答する端末が異なると結果が異なることが確認されました。しかし興味度や利用意向に関してはスマホからの回答がPCからの回答より低くなるという結果ではありませんでした。
以上の結果をまとめると:
- 標本枠効果があることを考えると、特定の端末からの回答者を制限せず、PC・スマホのいずれの端末からも回答できるように設計する(PC・スマホ併用調査=Mixed-Mode Research)
- 端末効果を最小限にとどめるためにも、いずれの端末から回答されても誤解や回答負荷を抑えて回答できるように設計する。このことを実現するために必要なものは次のとおりです(弊社では対応済み)。
- アンケートシステムがスマホ対応していること
- PC画面を意識するのではなく、スマホの画面を意識した画面設計を行い、同じ画面をPC画面に適用する(スマホ画面とPC画面の差をなくす)
Mixed-Mode Research ガイドライン
弊社ではPC・スマホの問題に対し、「Mixed-Mode Researchガイドライン」を作成しています。ガイドラインの作成にあたっては、自主調査を何回も実施し検証を行ってきました。
まとめ
Mixed-Mode Researchの考え方に基づいた調査設計を行うにあたっての留意点をまとめると以下のとおりです。
- 対象者の網羅性という観点から、特定の端末からの回答者を制限しない「PC・スマホ併用調査」を基本とする
- PCとスマホのどちらの端末から回答されても誤解や回答負荷を抑え、質の高いデータを収集できる調査設計をする
- 現状のPCからの回答を想定した調査設計ではなく、小さな画面のスマホからの回答を意識した調査設計を行い、同じ設計をPCにも適応する
- スマホ画面の「一覧性」を確保すべく、質問文・選択肢の書き方を工夫する(簡略化する)
- 集計・分析に当たってはPCあるいはスマホいずれかの端末からの回答結果を正とするのではなく、両端末からの回答結果を合算して集計し分析を行う
- PC及びスマホの回答端末比率を考慮すべきケースを理解し(たとえば継続調査)、必要なときにだけ回答端末比率を調整する(必要に応じウエイト付け集計を適応)
インターネット調査のサンプリング(標本抽出)について
ネット調査に限らず、標本調査(サーベイ)においては複数の調査間で比較を行うために、サンプルを均質化させることが重要です。従来のインターネット調査の実務で用いられるサンプリング方法は、居住地域(都道府県別)、性別×年齢の割付別に乱数を用いた「単純無作為抽出」が主流であると思われます。この方法だと、性別、年齢のデモグラフィック特性や大まかなジオグラフィック特性(1都3県、県別など)はコントロールされます。一方でたとえば千葉県の中で千葉市からいつも同じ人数が抽出される保障はありません。認知から購買にいたるファネルの効率を見たり、消費スタイルを見る継続調査などではたとえば市街地VS郊外の比率がその都度一定であることが必須です。サンプリング方式を「単純無作為抽出」から、母集団(ここでは楽天インサイトのアンケートモニター)を居住地域、性別×年齢の割付にプラスして郵便番号の順にならべ、その上で「系統抽出」を採用することでそれが可能になります。
弊社の実験結果を図表1と2に示しました。全国から30代男性をサンプルサイズを変えて、100人、500人、1000人、2000人抽出する(アンケートの配信リストを作成するイメージです)こと各20回繰り返しました。その結果1都3県から抽出される割合が最大の時と最小の時の差は、単純無作為抽出の場合、サンプルサイズが500以上の場合3~5%でした。一方系統抽出の場合、常に一定の割合で抽出されました。(図表1)
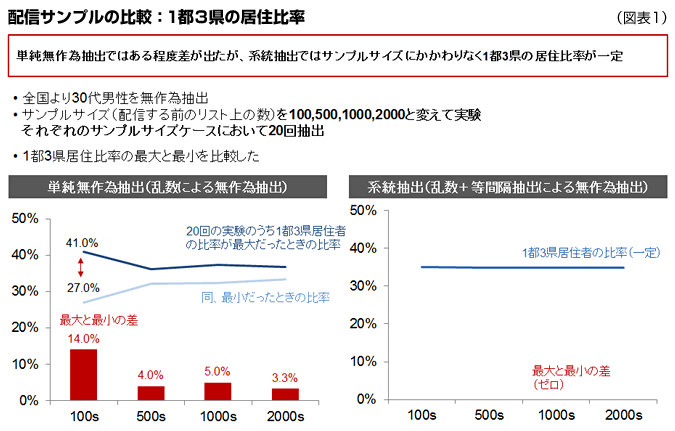
このデータだと一見単純無作為抽出でもよさそうですが、1都3県ではなく千葉県に絞って見た場合だいぶイメージが違ってきます。図表2のように、全国で1000人抽出した場合、単純無作為抽出の場合、千葉市から選ばれた人数は最大で16人(千葉県=50人)、最低で2人(千葉県=38人)とサンプル構成は大分ぶれます。一方系統抽出の場合、最大で9人(千葉県=43人)、最低で8人(千葉県=44人)と安定しています。
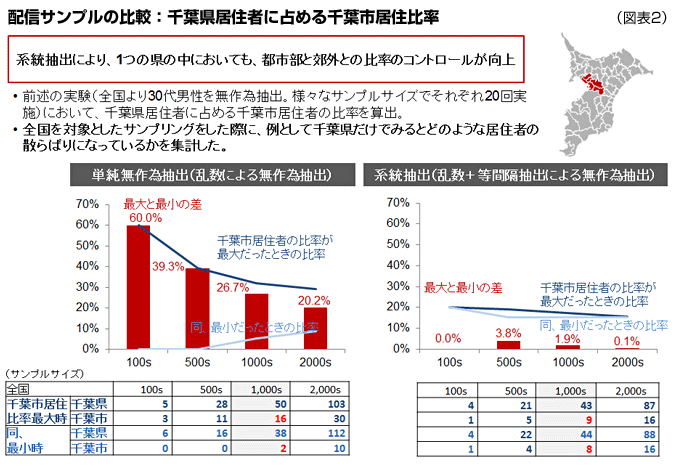
サンプリングは単純無作為抽出よりも系統抽出のほうが調査結果を安定させる(信頼性を増す)ことが証明されたと思いますが、さらにデータを安定させるには「回収率」を上げる工夫が必要です。
なお、エリアサンプリングで調査地点を抽出する場合(たとえば、住宅地図を用いて東京40km圏から30地点を抽出する)、その都度単純無作為抽出するよりは、系統抽出のほうがデータのぶれは少ないと思われます。さらに継続調査の場合、その都度の系統抽出よりは最初に系統抽出された調査地点の隣の地点(1回目のスタート番号に1を加えたものをスタート番号とする)を選んだほうがデータは安定すると思います。
次回はリサーチャーにとって、「陥りやすいワナについて」を予定しています。