リサーチャーは調査結果を操作できるか?
こんなパック旅行の例ではどうでしょう。
A案: フランス7泊8日の旅、¥98,000 ホテルのランク4つ星 オプションあり
B案: イタリア7泊8日の旅、¥98,000 ホテルのランク4つ星 オプションあり
これではどちらにするか、なかなか決めづらいのではないでしょうか?そこで旅行代理店の人がこんなプランもありますと言って、もう1案提案します。
C案: フランス6泊7日の旅、¥88,000 ホテルのランク3つ星 オプションなし
こうなると、Aを選ぶ人が多くなるのではないでしょうか?CはAより値段は少し安いのですが、日数やホテルでAよりは劣ります。AとBでは比較が困難ですが、AとCでは容易に比較が出来ます。種類が異なると比較は難しいのですが、同種の比較対象を提示することで人の行動を変えることができてしまうのです(出所:H.S.ダンフォード(2013).行動経済学の基本がわかる本 秀和システム)。
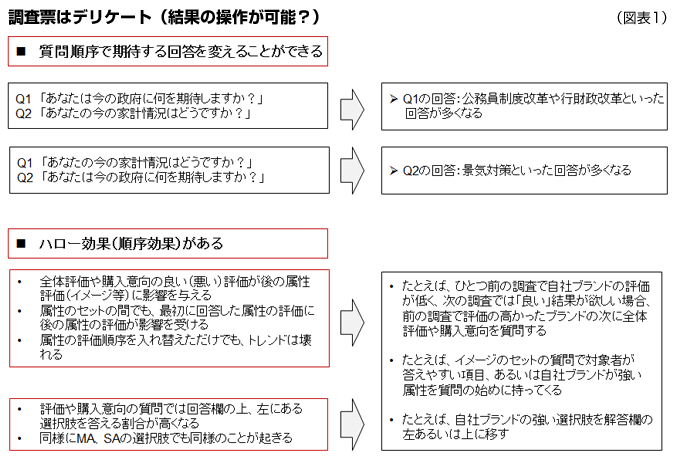
図表1【調査票はデリケート】をご覧ください。特に2つ目の例です。調査票のほんのちょっとした変更でもトレンドが崩れてしまう可能性があります。筆者はローテーションの組めないイメージ項目のセットでしたら、「親しみがある」とか「品質がよさそう」とか答えやすそうなものを最初に持ってくるようにしています。「お客様のことを考えている」とか「価格以上の価値がある」など回答するのに少し考えそうなものは後ろの方に持ってきます。トラッキング調査などで前回より評価が上がることが期待されている場合、次回の調査で当該ブランドの強いイメージを先に質問するようにすればイメージは全体的によくなる可能性が高くなります(もちろんそのようなことを意識的にやることは許されませんし、質問のローテーションも行うのですが)。
図表2は行動経済学の本からの抜粋です。Q1やQ2のような質問には、同じ内容であっても、人はポジティブな表現のほうを選ぶ傾向があります。調査に使うコンセプトの表現でも注意を払う必要があります。ネガティブな表現をしただけでポテンシャルの高いコンセプトが落とされることがままあります。
Q3ではAの2つのオプションで価格の高いほうを選んで貰おうとする意図が調査前にあれば、Bのようなデザインを組めばそのようになる確率は上がります。逆に安いほうを選びたいなら、もう1段階低い価格を設定すればそのようになる確率は高くなります。人は極端を嫌う傾向があるからです。

調査の精度を高める「暗黙知」
第28回のコラムでは非標本誤差(リサーチャーによるもの、インタビュアーによるもの、調査対象者によるもの)について、第30回のコラムでは「リサーチャーが陥りやすい罠」について述べましたが、ここではそれ以外の誤差をミニマイズする「暗黙知(らしいもの)」をいくつかあげたいと思います。
精度の高い測定のためには、調査データに影響を与えるバイアス(母集団の真の値との系統的なズレ)要因を一定にコントロールすることがなにより重要です。特に継続調査やA/Bテストでは調査対象者のデモグラフィックス(性・年齢・居住地域など)を合わせるのは当然のことです。しかし実務では、そのほかのバイアス要因をコントロールしない限り、正確な比較(計測)はできません。プロジェクトのゴールは、調査結果で差が出たら(出なかったら)、それはマーケティング刺激の効果があった(なかった)からですとリサーチャーとして自信を持っていえるよう、データのブレを未然に防ぐノウハウを持つことです。
たとえば:
- 継続調査を考えたとき、エリアサンプリングで住宅地図のメッシュを調査地点として、東京30km圏から50地点(n=500で1地点あたり10調査完了)を選ぶ場合、調査ごとに単純無作為抽出でその都度50地点を抽出するより、2回目の調査は第1回目の調査の隣の地点で調査したほうが、データの安定性は良くなるのではないでしょうか?(隣の地点というと非科学的に聞こえますが、住宅地図のメッシュに一連番号をふり系統抽出を行う。1回目の調査のスタート番号をiとしたら、2回目の調査のスタート番号はi+1とするということです)・・・詳しくは第29回のコラムの「系統抽出」を参照ください。
- 製品テストやコンセプトテスト(モナディックデザインのA/Bテストなど)で注意しなければならないのは、対象者の間でのユーザーの割合やヘビーユーザー・ライトユーザー・ノンユーザーの構成比が(ほぼ)同じであるかということです。これはトラッキング調査の場合にも当てはまります。これは特にトラッキング調査の場合しばしば見逃されます。
- ネット調査でしたら、配信日時のコントロールです。前回は火曜配信で48時間後に締め切り、今回は土曜配信で早く完了できたので24時間後に締め切り、というようなことが決してあってはいけません。
その他に関しては、図表3を参照ください。

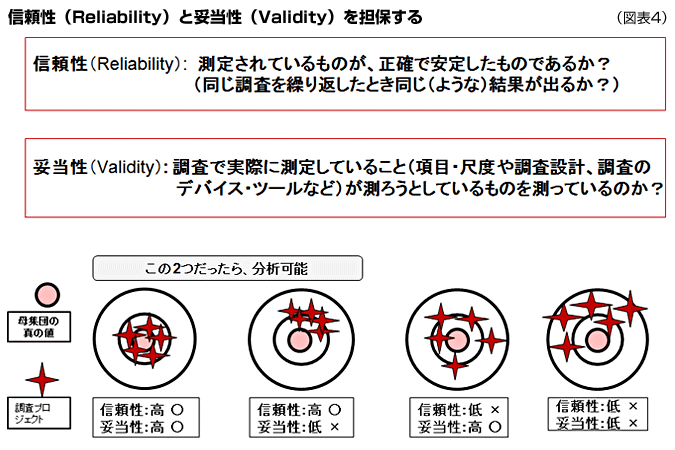
信頼性と妥当性
信頼性と妥当性の説明は大変難しいのですが、一言でいうと次のとおりです。
信頼性:
測定されているものが正確で安定したものであるか?言い換えると、同じ調査を繰り返したとき同じ(ような)結果が出るか?
妥当性:
調査で実際に測定していること(調査設計、調査票の項目・尺度、調査のデバイス・ツールなど)が自分の測りたいことを測っているのか?
理想の調査は信頼性も妥当性も高いものであることは当然です。母集団の真の値を推定するのに、インターネット調査を選択するのは妥当性にかけるといえます。しかし正しく設計されたインターネット調査は少なくとも信頼性は担保しているはずです(同じ設計で調査をすれば、何回繰り返してもほぼ同じ結果が出ます)。アクセスパネル全体を母集団と考えるなら、正しく設計されたネット調査は信頼性も妥当性も高いということができます。
調査品質を担保するために
クライアントにとって価値ある情報を提供するためには、信頼性のあるデータの収集が基本です。データを収集する企業・団体は市場調査会社の他にもありますが、マーケティング・リサーチ会社だけが誰もが信頼できる、正確で独立した誰からも影響を受けない第三者情報を提供出来るのです(JMRA会員社はマーケティング・リサーチ綱領、JMRA市場調査品質基準、調査マネジメントガイドラインや各種ガイドラインに則って調査を行っているからです)。
結論として、高い調査品質を決定づけるのは以下のことであると私は思っています。
- 調査対象者への配慮(長すぎない、見やすい、わかりやすい調査票など)
- 科学的アプローチの採用(サンプリング、統計、様々なモデルの援用など)
- 適切な調査のツール・デバイス(調査画面のスマホ対応など)
- リサーチャーの教育(調査プロセスについての理解、消費者行動、マーケティング理論の理解など)
- バイアスをコントロールする、あるいはエラーをミニマイズする調査会社内に蓄積された暗黙知
補足:行動経済学について
「人間は首尾一貫した選好をもちあわせており、それを最大化すべく行動する」(経済的合理性)というのが伝統的経済学の大前提でした。しかし私たちが物事を判断し、選択する行動は必ずしもそうではありません。既存の理論では合理的に説明できない行動は、アノマリー(逸脱)として片づけられていました。行動経済学では、人間が完璧に合理的な選択をするとは考えません。心理学の知見や実験データを援用しながらアノマリーの説明を試み、従来になかった経済理論を構築するのが特徴です。
リサーチャーとしては、実験のデザインの組み方・測定方法にも大変興味を惹かれます。様々な実験の紹介は調査デザインの引き出しを増やしてくれます。
参考となる本をいくつか紹介します。
- 「選択の科学…コロンビア大学ビジネススクール特別講義」シーナ・アイエンガー著/櫻井裕子訳、文藝春秋(文春文庫にもあります)
- 「ファスト&スロー、あなたの意志はどのように決まるのか?」(上下)ダニエル・カーネマン著/村井章子訳、ハヤカワ・ノンフィクション文庫・・・筆者はノーベル経済学賞受賞者
- 「予想どおりに不合理」ダン・アリエリ著/熊谷淳子訳、ハヤカワ・ノンフィクション文庫・・・筆者はイグ・ノーベル賞受賞者
今回で「調査の信頼性を担保する」は終了です。次回から新しいシリーズ(テーマ未定)が始まります。